When does Bayesian inference shatter?
In the spring of last year, a paper with the title Bayesian Brittleness: Why no Bayesian model is “good enough” was put on the arXiv. The authors (Houman Owhadi, Clint Scovel, Tim Sullivan, henceforth OSS) later posted a followup entitled When Bayesian inference shatters. When published, this work was commented on in a number of stats blogs I follow, including Xian’s Og and Error Statistics Philosophy. Christian Hennig wrote up this nice nickel summary:
One of the author’s results (if I could nominate one as the most important, I’d choose this one) says that if you replace your model by another one which is in an arbitrarily close neighborhood (according to the [Prokhorov] metric discussed above), the posterior expectation could be as far away as you want. Which, if you choose the right metric, means that you replace your sampling model by another one out of which typical samples *look the same*, and which therefore can be seen as as appropriate for the situation as the original one.
Note that the result is primarily about a change in the sampling model, not the prior, although it is a bit more complex than that because if you change the sampling model, you need to adapt the prior, too, which is appropriately taken into account by the authors as far as I can see.
My own reaction was rather less impressed; I tossed off,
Conclusion: Don’t define “closeness” using the TV [that is, total variation] metric or matching a finite number of moments. Use KL divergence instead.
In response to a a request by Mayo, OSS wrote up a “plain jane” explanation which was posted on Error Statistics Philosophy a couple of weeks later. It confirmed Christian’s summary:
So the brittleness theorems state that for any Bayesian model there is a second one, nearly indistinguishable from the first, achieving any desired posterior value within the deterministic range of the quantity of interest.
That sounds pretty terrible!
—
This issue came up for discussion in the comments of an Error Statistics Philosophy post in late December.
MAYO: Larry: Do you know anything about current reactions to, status of, the results by Houman Owhadi, Clint Scovel and Tim Sullivan? Are they deemed relevant for practice? (I heard some people downplay the results as not of practical concern.)
LARRY: I am not aware of significant rebuttals.
COREY: I have a vague idea that any rebuttal will basically assert that the distance these authors use is too non-discriminating in some sense, so Bayes fails to distinguish “nice” distributions from nearby (according to the distance) “nasty” ones. My intuition is that these results won’t hold for relative entropy, but I don’t have the knowledge and training to develop this idea — you’d need someone like John Baez for that.
OWHADI (the O in OSS): Well, one should define what one means by “nice” and “nasty” (and preferably without invoking circular arguments).
Also, it would seem to me that the statement that TV and Prokhorov cannot be used (or are not relevant) in “classical” Bayes is a powerful result in itself. Indeed TV has not only been used in many parts of statistics but it has also been called the testing metric by Le Cam for a good reason: i.e. (writing n the number of samples), Le Cam’s Lemma state that
1) For any n, if TV is close enough (as a function of n) all tests are bad.
2) Given any TV distance, with enough sample data there exists a good test.
Now concerning using closeness in Kullback–Leibler (KL) divergence rather than Prokhorov or TV, observe that (as noted in our original post) closeness in KL divergence is not something you can test with discrete data, but you can test closeness in TV or Prokhorov. In other words the statement “if the true distribution and my model are close in KL then classical Bayes behaves nicely” can be understood as “if I am given this infinite amount of information then my Bayesian estimation is good” which is precisely one issue/concern raised by our paper (brittleness under “finite” information).
Note also that, the assumption of closeness in KL divergence requires the non-singularity of the data generating distribution with respect to the Bayesian model (which could be a very strong assumption if you are trying to certify the safety of a critical system and results like the Feldman–Hajek Theorem tell us that “most” pairs of measures are mutually singular in the now popular context of stochastic PDEs).
In preparing a reply to Owhadi, I discovered a comment written by Dave Higdon on Xian’s Og a few days after OSS’s “plain jane” summary went up on Error Statistics Philosophy. He described the situation in concrete terms; this clarified for me just what it is that OSS’s brittleness theorems demonstrate. (Christian Hennig saw the issue too, but I couldn’t follow what he was saying without the example Higdon gave. And OSS are perfectly aware of it too — this post represents me catching up with the more knowledgeable folks.)
Suppose we judge a system safe provided that the probability that the random variable X exceeds 10 is very low. We assume that X has a Gaussian distribution with known variance 1 and unknown mean μ, the prior for which is
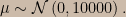
This prior doesn’t encode a strong opinion about the prior predictive probability of the event X > 10 (i.e., disaster).
Next, we learn about the safety of the system by observing a realization of X, and it turns out that the datum x is smaller than 7 and the posterior predictive probability of disaster is negligible. Good news, right?
OSS say, not so fast! They ask: suppose that our model is misspecified, and the true model is “nearby” in Prokhorov or TV metric. They show that for any datum that we can observe, the set of all nearby models includes a model that predicts disaster.
What kinds of model misspecifications do the Prokhorov and TV metrics capture? Suppose that the data space has been discretized to precision 2ϵ, and consider the set of models in which, for each possible observable datum x0, the probability density is
![\pi\left(x;\mu\right)\propto\begin{cases}\exp\left\{ -\frac{1}{2}\left(x-\mu\right)^{2}\right\} \times\chi\left(x\notin\left[x_{0}-\epsilon,x_{0}+\epsilon\right]\right), & \mu\le20,\\\exp\left\{ -\frac{1}{2}\left(x-\mu\right)^{2}\right\} , & \mu>20,\end{cases}](https://s0.wp.com/latex.php?latex=%5Cpi%5Cleft%28x%3B%5Cmu%5Cright%29%5Cpropto%5Cbegin%7Bcases%7D%5Cexp%5Cleft%5C%7B+-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu%5Cright%29%5E%7B2%7D%5Cright%5C%7D+%5Ctimes%5Cchi%5Cleft%28x%5Cnotin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%5Cright%29%2C+%26+%5Cmu%5Cle20%2C%5C%5C%5Cexp%5Cleft%5C%7B+-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu%5Cright%29%5E%7B2%7D%5Cright%5C%7D+%2C+%26+%5Cmu%3E20%2C%5Cend%7Bcases%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
in which χ(.) is the indicator function. For any specific value of μ, all of the models in the above set are within a small ball centered on the Gaussian model, where “small” is measured by either the Prokhorov or TV metric. (How small depends on ϵ.) Each model embodies an implication of the form:
![\mu\le20\Rightarrow x\notin\left[x_{0}-\epsilon,x_{0}+\epsilon\right];](https://s0.wp.com/latex.php?latex=%5Cmu%5Cle20%5CRightarrow+x%5Cnotin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%3B&bg=ccbbaa&fg=000000&s=0&c=20201002)
by taking the contrapositive, we see that this is equivalent to:
![x\in\left[x_{0}-\epsilon,x_{0}+\epsilon\right]\Rightarrow\mu>20.](https://s0.wp.com/latex.php?latex=x%5Cin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%5CRightarrow%5Cmu%3E20.&bg=ccbbaa&fg=000000&s=0&c=20201002)
Each of these “nearby” models basically modifies the Gaussian model to enable one specific possible datum to be a certain indicator of disaster. Thus, no matter which datum we actually end up observing, there is a “nearby” model for which both (i) typical samples are basically indistinguishable from typical samples under our assumed Gaussian model, and yet (ii) the realized datum has caused that “nearby” model, like Chicken Little, to squawk that the sky is falling.
OSS have proved a very general version of the above phenomenon: under the (weak) conditions they assume, for any given data set that we can observe, the set of all models “near” the posterior distribution contains a model that, upon observation of the realized data, goes into (the statistical model equivalent of) spasms of pants-shitting terror.
There’s nothing special to Bayes here; in particular, all of the talk about the asymptotic testability of TV- and/or Prokhorov-distinct distributions is a red herring. The OSS procedure stymies learning about the system of interest because the model misspecification set is specifically constructed to allow any possible data set to be totally misleading under the assumed model. Seen in this light, OSS’s choice of article titles is rather tendentious, don’t you think? If tendentious titles are the order of the day, perhaps the first one could be called As flies to wanton boys are we to th’ gods: Why no statistical model whatsoever is “good enough” and the second one could be called Prokhorov and total variation neighborhoods and paranoid psychotic breaks with reality.

Corey,
You’re absolutely right about this. This entire episode merely reflects that anyone who is incapable of thinking of probability distributions as anything other than frequency distributions can generate an infinite supply of seeming “paradoxes”, “contradictions”, and “problems”. While such results tell you a great deal about the geometer pronouncing them, they tell you nothing about Bayes.
Any method that interprets probability distributions as frequency distributions will have brittleness (in some sense) to it. So this is ultimately a problem for Frequentists though and not Bayesians. A non frequentist interpretation of P(x|H) can be viewed as a kind of sensitivity analysis. If P(x|H) is thought of as a way to encode our ignorance about some x_true and the high probability manifold of P(x|H) is big enough to include every x consistent with H, then averaging over P(x|H) is a way to test how sensitive the final answer is to reasonable changes in x_true. If done properly it provides most of the robustness Bayesians need in practice.
That is why K-L divergence is the right one to use (it really should just be called “Entropy”: Gibbs used it explicitly in his Statistical Mechanics and proved it’s key mathematical properties half a century before Kullback). The K-L divergence between two distributions P_2, P_1 not only compares the size of the high probability manifolds of P_2, P_1, but it also judges how well they overlap. Since the size and location of the high probability manifold is everything, that makes K-L the right tool to use.
Incidently, an alternative way to think about K-L is if P_1 =P(x|H) and P_2=P(x|HJ), then the K-L divergence is a measure of how much additional “information” J is needed to go from P_1 to P_2.
That entire paragraph by Owhadi beginning “…observe that … closeness in KL divergence is not something you can test with discrete data,” is telling in the extreme. Bayesian probability distributions P(x|H) are theoretically derived from H, not frequency distributions to be “tested” from data. This echo’s something I’ve seen repeated by Mayo and some of her acolyte’s to the effect that priors require “infinite data” or a least represent “infinite knowledge” if considered an assumption.
Such ideas are insanely stupid. So the fact that they continue to be uttered by smart people who’ve thought about them a long time indicates that they’ll never really understand Bayes. They will continue to interpret probability distributions solely as frequency distributions, unable to imagine any other possibility, and after you’ve shot this particular example down they will move on to another one.
For the record: I’ve never claimed that assigning priors requires infinite data or infinite knowledge. However, I do recall J. Berger saying:
“to elicit all features of a subjective prior [about theta], one must infinitely accurately specify a (typically) infinite number of things.”(J. Berger 2006, p. 397) http://ba.stat.cmu.edu/journal/2006/vol01/issue03/berger.pdf
I withdrawal the claim that you endorsed that viewpoint rather than merely discussed it.
Professor Owhadi replied, and I rejoined.
That whole discussion continues to illuminate. In their mind if two distributions P_1 and P_2 can be viewed as valid (according to some criteria) approximations to some (frequency) distribution then there’s nothing to distinguish between then and if they give very different answers then that’s a big problem. The analyst presumably has no guidance on which to choose, and the answers they ultimately get depend on a whim.
There’s no hint of the idea that P_1 and P_2 are not equally good for Bayesians. The goal of creating P(x|H) would be something like “find the least informative distribution that doesn’t contradict H”. Even if P_1 and P_2 are equally compatible with H, they aren’t going to be equally informative. That gives us a way to decide between them. What they think of as equally valid frequency distributions aren’t even close to being equally desirable Bayesian probability distributions.
Hi Corey, back from my holidays I go through my favourite stats blogs and am delighted to see that you write something manageable to read in finite time after I gave up on the comments section of the Wasserman-post on Mayo’s blog in the first go.
What I can add for the moment is that I think indeed that what’s needed is a proper account of what kind of prior model could be “bad” for what reasons, despite being in a small TV/Prokhorov-neighbourhood of something reasonable.
I think that some “engineer-logic” could help here, thinking about what kind of thing we want to do with the modelling/inference apart from “hitting the true model”. Entsophy’s comments go in this direction although I remain skeptical about the KL-divergence (probably because of my “Daviesianism” when it comes to densities).
In any case, I think that Owhadi et al.’s work allow us to learn something important about Bayesian statistics, revealing that there are critical features of prior models that people haven’t thought of enough yet.
Surely the point of the paper was to remind us that Bayesian inference generally relies for its credibility on something like Occam’s razor, otherwise it can be very misleading.
I don’t think the point of the paper was to remind us of anything in particular. Owhadi et al. were trying to make substantive new claims. I deny that the claims they made were substantive, because the misspecification set they consider is too pathological, leading them to prove too much — their procedure would discredit any statistical model to which it was applied.
Your ‘too pathological’ corresponds to my ‘would be rejected by Occam’s razor’. My point is that your Bayesianism presupposes that we have a good appreciation of what is possible and what is pathological. I am uncertain that this is generally the case, and certain that it is not always.
I agree that if one is paranoid then one shouldn’t trust any statistical model. But then there seems no reason to suppose that economies etc actually are stochastic, and hence no reason to absolutely believe any statistical model. Maybe Bayesianism is as good as it gets, but it isn’t absolutely, unconditionally ‘true’, is it?
I don’t disagree with you.
Let me just add (with no sarcasm at all!), thank you for your interest!