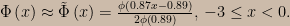I’ve been reading Mayo’s recent book, Statistical Inference as Severe Testing, and I’ve arrived at the chapter in which she offers criticisms of the Likelihood Principle (LP) (recall that the LP says that the data should enter into the inference only through the likelihood function). In contrast, Mayo’s severity approach directs us to examine a procedure’s capacity to detect errors; in practice this means computing, post-data, how frequently a procedure’s actual conclusion could have been reached in error in hypothetical repetitions. Data enters into the inference as part of a sampling distribution calculation, so severity and the LP are incompatible. In this post I’ll examine two of the scenarios Mayo presents while criticizing the LP; I aim to demonstrate that in the first scenario the criticism Mayo offers is founded on a technical error, and in the second scenario the criticism Mayo offers may bite against likelihood theorists but is toothless for Bayesians.
The first scenario concerns an investment fund that deceptively advertises portfolio picks made by the “Pickrite method”:
[Jay] Kadane[, a prominent Bayesian,] is emphasizing that Bayesian inference is conditional on the particular outcome. So once x is known and fixed, other possible outcomes that could have occurred but didn’t are irrelevant. Recall finding that Pickrite’s procedure was to build k different portfolios [with a random selection of stocks] and report just the one that did best. It’s as if Kadane is asking: “Why are you considering other portfolios that you might have been sent but were not, to reason from the one that you got?” Your answer is: “Because that’s how I figure out whether your boast about Pickrite is warranted.” With the “search through k portfolios” procedure, the possible outcomes are the success rates of the k different attempted portfolios, each with its own null hypothesis. The actual or “audited” P-value is rather high, so the severity for H: Pickrite has a reliable strategy, is low (1 – p). For the holder of the LP to say that, once x is known, we’re not allowed to consider the other chances that they gave themselves to find an impressive portfolio, is to put the kibosh on a crucial way to scrutinize the testing process.
This argument is a straw man caused by a misunderstanding — an unintentional equivocation, if that’s a thing, on the phrase “other portfolios that might have been sent to you but were not”. Now, nothing here turns on the fact that the scenario doesn’t completely specify the distribution of portfolio returns. We are told that the stocks are picked at random, so the portfolio returns are independent and identically distributed random variables; the argument would seem to continue to apply if we specify that portfolio rates of return have some particular known distribution. Mayo tells us that according to a holder of the LP, once x is known we’re not allowed to consider the other chances that the Pickrite method provides for finding an impressive portfolio. Suppose portfolio rates of return are known to have, say, an exponential distribution with unknown mean μ; in that case, the only way I can see to cash out Mayo’s argument in math is to say that she thinks the LP obliges us to use the likelihood function ℓ(μ; x) arising from the exponential density for a single value,
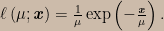
But this is simply wrong. The argument overlooks the fact that the LP doesn’t forbid us from taking the data collection mechanism into account (including mechanisms of missing data) when constructing the likelihood function itself. We’ve been told that we were presented with just the best result from out of k portfolios that were built, so to construct the likelihood we take the probability density for all k rates of return and we integrate out the k – 1 unobserved rates of return that were smaller than the one we do get to see. In statistical jargon, our likelihood function arises from the probability density for the largest order statistic; the general formula for the density of an order statistic can be found here. Assuming as before that rates of return follow an exponential distribution, the correct likelihood arising in this scenario would be
![\ell\left(\mu;\mathbf{\textbf{\textit{x}}}\right)=\frac{1}{\mu}\exp\left(-\frac{\mathbf{\textbf{\textit{x}}}}{\mu}\right)\left[1-\exp\left(-\frac{\mathbf{\textbf{\textit{x}}}}{\mu}\right)\right]^{k-1}.](https://s0.wp.com/latex.php?latex=%5Cell%5Cleft%28%5Cmu%3B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%5Cright%29%3D%5Cfrac%7B1%7D%7B%5Cmu%7D%5Cexp%5Cleft%28-%5Cfrac%7B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%7D%7B%5Cmu%7D%5Cright%29%5Cleft%5B1-%5Cexp%5Cleft%28-%5Cfrac%7B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%7D%7B%5Cmu%7D%5Cright%29%5Cright%5D%5E%7Bk-1%7D.&bg=ccbbaa&fg=000000&s=0&c=20201002)
In fact, in this scenario an error statistician would use precisely this probability model to compute “audited” p-values and confidence intervals, and since the parameter being estimated is a scale parameter we would have the standard numerical agreement of frequentist confidence intervals and Bayesian credible intervals (under the usual reference prior for scale parameters).
Kadane might very well ask, “Why are you considering other portfolios that you might have been sent but were not, to reason from the one that you got?” But the portfolios he would be referring to aren’t the other portfolios in the sample that we didn’t get to see — a holder of the LP agrees that those portfolios need to be taken into consideration. The “other portfolios the you might have been sent but were not” are the ones that might have arisen in hypothetical replications of the whole data-generating process, that is, other best portfolios selected out of k of them. Those are the “other portfolios” that likelihood theorists and Bayesians consider irrelevant. (The misunderstanding of the referent of “other portfolios” is the unintentional equivocation.) Of course, an error statistician disagrees that they are irrelevant — they’re implicit in the p-value computation — but this is a separate issue.
So that disposes of the Pickrite scenario and the cherry-picking argument against the LP. The second scenario is attributed to Allan Birnbaum, a statistician who started as a likelihood theorist but later abandoned those views due to the inability of likelihoods to control error probabilities. Here’s how Mayo presents it:
A single observation is made on X, which can take values 1, 2, …, 100. “There are 101 possible distributions conveniently indexed by a parameter θ taking values 0, 1, …, 100″ (ibid.) We are not told what θ is, but there are 101 possible point hypotheses about the value of θ: from 0 to 100. If X is observed to be r, written X = r (r ≠ 0), then the most likely hypothesis is θ = r: in fact, Pr(X = r | θ = r) = 1. By contrast, Pr(X = r | θ = 0) = 0.01. Whatever value r that is observed, hypothesis θ = r is 100 times as likely as is θ = 0. Say you observe X = 50, then H: θ = 50 is 100 times as likely as is θ = 0. So “even if in fact θ = 0, we are certain to find evidence apparently pointing strongly against θ = 0, if we allow comparisons of likelihoods chosen in light of the data” (Cox and Hinkley 1974, p. 52). This does not happen if the test is restricted to two preselected values. In fact, if θ = 0 the probability of a ratio of 100 in favor of the false hypothesis is 0.01.
It’s apparent that this scenario is designed to challenge the views of likelihood theorists more than those of Bayesians. Nevertheless, Mayo writes, “Allan Birnbaum gets the prize for inventing chestnuts that deeply challenge both those who do, and those who do not, hold the Likelihood Principle!” And since Bayesians do hold the LP, let’s see what challenges Birnbaum’s chestnut presents for us Bayesians.
The contention is that if we let the data determine which non-zero θ value to consider then we are certain to find evidence apparently pointing strongly against θ = 0 even if it is in fact the case that θ = 0. That sounds pretty bad!
First we need to say what “evidence pointing against a hypothesis” means for Bayesians. Later in the book Mayo discusses Bayesian epistemology as a school of thought within academic philosophy, including various proposed numerical measures of confirmation. We don’t need to touch on those complications here; for us it will be enough to say that the data provide evidence against a hypothesis when the posterior odds against it are higher than the prior odds.
Because we’re looking at the odds against θ = 0 it is helpful to first decompose the hypothesis space into θ = 0 and its negation θ ≠ 0 and then assign prior probability mass conditional on θ ≠ 0 to the non-zero values, call them θ’, that θ might take. Given such a decomposition, this is the odds form of Bayes’s theorem in this problem:
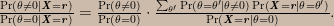
The ratio on the left is the posterior odds, the first ratio on the right is the prior odds, and the second ratio on the right is the update factor. In the sum in the numerator of the update factor, all of the Pr(X = r | θ = θ’) terms are zero except for the one in which θ’ = r; these terms act as an indicator function selecting just the prior probability for the non-zero θ value corresponding to the observed data value. Since Pr(X = r | θ = 0) = 0.01 we can write
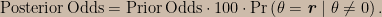
The factor of 100 is the likelihood ratio; perhaps unexpectedly, it can be seen that the likelihood ratio is not only term in the update factor. The Pr(θ = r | θ ≠ 0) term is a funny-looking thing — it’s a prior probability and yet it seems to involve the data. It should be understood to mean “the prior probability, conditional on θ ≠ 0, for the value of θ corresponding to the datum that was later observed”.
Now we can imagine all sorts of background information that might inform our prior probabilities; in this respect the statement of the problem is underspecified. Suppose nevertheless that this is all we are given; then it seems appropriate to specify a uniform conditional prior distribution, Pr(θ = θ’ | θ ≠ 0) = 0.01. Then no matter what value the datum takes, the update factor is identically one; that is, for this prior distribution the evidence in the data is certain to neither cut against nor in favour of θ = 0.
If we have information that justifies a non-uniform conditional prior distribution then for some values of θ the prior will be larger than 0.01; a corresponding datum would result in an update factor greater than one and thus be evidence against θ = 0. But in this situation there must be other values of θ for which the prior is smaller than 0.01, and a corresponding datum would result in an update factor smaller than one and thus be evidence in favour of θ = 0. So contrary to what Cox and Hinkley say holds for likelihood theorists, we Bayesians are never certain of finding evidence against θ = 0 even when it is in fact the case — the closest we get is being certain that the data provide no evidence one way or the other.
I wonder if this chestnut of Birnbaum’s poses any challenge for the severity concept…
![p_{X,Y}\left(x,y \right )\propto\exp\left[-\frac{1}{2}\left(x^2+y^2\right ) \right ].](https://s0.wp.com/latex.php?latex=p_%7BX%2CY%7D%5Cleft%28x%2Cy+%5Cright+%29%5Cpropto%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x%5E2%2By%5E2%5Cright+%29+%5Cright+%5D.&bg=ccbbaa&fg=000000&s=0&c=20201002)
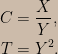
![\begin{aligned}p_{C,T}\left(c,t \right )&\propto\exp\left[-\frac{1}{2}\left(1+c^2\right )t \right ]\\&=\left ( \frac{1}{1+c^2} \right )\left \{ \frac{1}{2}\left(1+c^2\right )\exp\left[-\frac{1}{2}\left(1+c^2\right )t \right ]\right \}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7Dp_%7BC%2CT%7D%5Cleft%28c%2Ct+%5Cright+%29%26%5Cpropto%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29t+%5Cright+%5D%5C%5C%26%3D%5Cleft+%28+%5Cfrac%7B1%7D%7B1%2Bc%5E2%7D+%5Cright+%29%5Cleft+%5C%7B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29t+%5Cright+%5D%5Cright+%5C%7D.%5Cend%7Baligned%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
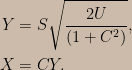
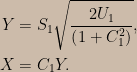
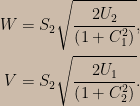


![\begin{aligned}&\Pr\left(\bar{\mathrm{X}}_{4}>165;\mu\right)\Pr\left(\bar{\mathrm{X}}_{4}>q_{4}\left(\alpha,\mu\right)\mid\bar{\mathrm{X}}_{4}>165;\mu\right)\\&+\Pr\left(\bar{\mathrm{X}}_{4}\le165;\mu\right)\Pr\left(\bar{\mathrm{X}}_{100}>q_{100}\left(\alpha,\mu\right)\mid\bar{\mathrm{X}}_{4}\le165;\mu\right)\\=&\left(1-\alpha\right)\left[\Pr\left(\bar{\mathrm{X}}_{4}>165;\mu\right)+\Pr\left(\bar{\mathrm{X}}_{4}\le165;\mu\right)\right]\\=&1-\alpha\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%26%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3Eq_%7B4%7D%5Cleft%28%5Calpha%2C%5Cmu%5Cright%29%5Cmid%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%5C%5C%26%2B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B100%7D%3Eq_%7B100%7D%5Cleft%28%5Calpha%2C%5Cmu%5Cright%29%5Cmid%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5C%5C%3D%26%5Cleft%281-%5Calpha%5Cright%29%5Cleft%5B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%2B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5Cright%5D%5C%5C%3D%261-%5Calpha%5Cend%7Baligned%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)