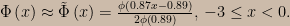The first post on this blog described my blogging agenda. It was pinned to the top of the blog but it’s badly out of date so I’ve unpinned it. When I left off, I was about half way though my explanation of severity and I was about to embark on a description of what Mayo calls “howlers” – calumnies cast upon the classical tools of frequentist statistics that are addressed by the severity concept. The severity concept and its formal mathematical incarnation, the SEV function, are explained in Mayo and Spanos’s 2011 article Error Statistics, as are the ways in which the SEV function addresses typical criticisms (which are helpfully written in bold font in numbered and center-justified boxes, but SEV isn’t introduced until howler #2).
I recommend that people who want to really understand the severity argument read the above-linked paper, but for completeness’s sake let’s have a look at how the SEV function formalizes severity arguments. (Since I’ll be discussing both frequentist and Bayesian calculations I’ll use the notation Fr ( · ; · ) for frequency distributions and Pl ( · | · ) for plausibility distributions.) The examples I’ve seen typically involve nice models and location parameters, so let’s consider an irregular model with a scale parameter. Consider a univariate uniform distribution with unknown support; suppose that the number of data points, n, is at least two and we aim to assess the warrant for claims about the width of the support, call it ∆, using the difference between the largest and smallest data values, D = Xmax – Xmin, as our test statistic. (This model is “irregular” in that the support of the test statistic’s sampling distribution depends on the parameter.) Starting from the joint distribution of the order statistics of the uniform distribution one can show that D is a pivotal statistic satisfying
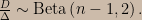
Severity reasoning works like this: we aim to rule out a particular way that some claim could be wrong, thereby avoiding one way of being in error in asserting the claim. The way we do that is by carrying out a test that would frequently detect such an error if the claim were in fact wrong in that particular way. We attach the error detection frequency to the claim and say that the claim has passed a severe test for the presence of the error; the error detection frequency quantifies just how severe the test was.
To cash this out in the form of a SEV function we need a notion of accordance between the test statistic and the statistical hypothesis being tested. In our case, higher observed values of D accord with higher hypothesized values of ∆ (and in fact, values of ∆ smaller than the observed value of D are strictly ruled out). SEV is a function with a subjunctive mood; we don’t necessarily carry out any particular test but instead look at all the tests we might have carried out. So: if we were to claim that ∆ > δ when ∆ ≤ δ was true then we’d have committed an error. Smaller observed values of D are less in accord with larger values of ∆, so we could have tested for the presence of the error by declaring it to be present if the observed value of D were smaller than some threshold d. Now, there are lots of possible thresholds d and also lots of ways that the claim “∆ > δ” could be wrong – one way for each value of ∆ smaller than δ – but we can finesse these issues by considering the worst possible case. In the worst case the test is just barely passed, that is, the observed value of D is on the test’s threshold, and ∆ takes the value that minimizes the frequency of error detection and yet still satisfies ∆ ≤ δ. (Mayo does more work to justify all of this than I’m going to do here.) Thus the severity of the test that the claim “∆ > δ” would have passed is the worst-case frequency of declaring the error to be present supposing that to actually be the case:

in which D is (still) a random variable and d is the value of D that was actually observed in the data at hand.
In every example of a SEV calculation I’ve seen, the minimum occurs right on the boundary — in this case, at ∆ = δ. It’s not clear to me if Mayo would insist that the SEV function can only be sensibly defined for models in which the minimum is at the boundary; that restriction seems implicit in some of the things she’s written about accordance of test statistics with parameter values. In any event it holds in this model, so we can write

What this says is that to calculate the SEV function for this model we stick (d / δ) into the cdf for the Beta (n – 1, 2) distribution and allow δ to vary. I’ve written a little web app to allow readers to explore the meaning of this equation.
As part of my blogging agenda I had planned to find examples of prominent Bayesians asserting Mayo’s howlers. At one point Mayo expressed disbelief to me that I would call out individuals by name as I demonstrated how the SEV function addressed their criticism, but this would have been easier for me than she thought. The reason is that in all of the examples of formal SEV calculations that I have ever seen (including the one I just did above), it’s been applied to univariate location or scale parameter problems in which the SEV calculation produces exactly the same numbers as a Bayesian analysis (using the commonly-accepted default/non-informative/objective prior, i.e., uniform for location parameters and/or for the logarithm of scale parameters; this SEV calculator web app for the normal distribution mean serves equally well as a Bayesian posterior calculator under those priors). So I wasn’t too concerned about ruffling feathers – because I’m no one of consequence, but also because a critique that goes “criticisms of frequentism are unfair because frequentists have figured out this Bayesian-posterior-looking thing” isn’t the sort of thing any Bayesian is going to find particularly cutting, no matter what argument is adduced to justify the frequentist posterior analogue. In any event, at this remove I find I lack the motivation to actually go and track down an instance of a Bayesian issuing each of the howlers, so if you are one such and you’ve failed to grapple with Mayo’s severity argument – consider yourself chided! (Although I can’t be bothered to find quotes I can name a couple of names off the top of my head: Jay Kadane and William Briggs.)
Because of this identity of numerical output in the two approaches I found it hard to say whether the SEV functions computed and plotted in Mayo and Spanos’s article and in my web app illustrate the severity argument in a way that actually supports it or if they’re just lending it an appearance of reasonability because, through a mathematical coincidence, they happens to line up with default Bayesian analyses. Or, perhaps default Bayesian analyses seem to give reasonable numbers because, through a mathematical coincidence, they happen to line up with SEV – a form of what some critics of Bayes have called “frequentist pursuit”. To help resolve this ambiguity I sought to create an intuition pump: an easy-to-analyze statistical model that could be subjected to extreme conditions in which intuition would strongly suggest what sorts of conclusions were reasonable. The outputs of the formal statistical methods — the SEV function on the one hand and a Bayesian posterior on the other — could be measured relative to these intuitions. Of course, sometimes the point of carrying out a formal analysis is to educate one’s intuition, as in the birthday problem; but in other cases one’s intuition acts to demonstrate that the formalization isn’t doing the work one intended it to do, as in the case of the integrated information theory of consciousness. (The latter link has a discussion of “paradigm cases” that is quite pertinent to my present topic.)
When I first started blogging about severity the idea I had in mind for this intuition pump was to apply an optional stopping data collection design to the usual normal distribution with known variance and unknown mean. Either one or two data points would be observed, with the second data point observed only if the first one was within some region where it would be desirable to gather more information. This kind of optional stopping design induces the same likelihood function (up to proportionality) as a fixed sample size design, but the alteration of the sample space gives rise to very different frequency properties, and this guarantees that (unlike in the fixed sample sized design) the SEV function and the Bayesian posterior will not agree in general.
Now, the computation of a SEV function demands a test procedure that gives a rejection region for any Type I error rate and any one-sided alternative hypothesis; this is because to calculate SEV we need to be able to run the test procedure backward and figure out for each possible one-sided alternative hypothesis what Type I error rate would have given rise to a rejection region with the observed value of the test statistic right on the boundary. (If that seemed complicated, it’s because it is.) In the optional stopping design the test procedure would involve two rejection regions, one for each possible sample size, and a collect-more-data region; given these extra degrees of freedom in specifying the test I found myself struggling to define a procedure that I felt could not be objected to – in particular, I couldn’t handle the math needed to find a uniformly most powerful test (if one even exists in this setup). The usual tool for proving the existence of uniformly powerful tests, the Karlin-Rubin theorem, does not apply to the very weird sample space that arises in the optional stopping design – the dimensionality of the sample space is itself a random variable. But as I worked with the model I realized that optional stopping wasn’t the only way to alter the sample space to drive a wedge between the SEV function and the Bayesian posterior. When I examined the first stage of the optional stopping design in which the collect-more-data region creates a gap in the sample space, I realized that chopping out a chunk of the sample space and just forgetting about the second data point would be enough to force the two formal statistical methods to disagree.
An instance of such a model was described in my most recent post: a normal distribution with unknown μ in ℝ and unit σ and a gap in the sample space between -1 and 3, yielding the probability density
![f\left(x;\mu\right)=\begin{cases} \frac{\phi\left(x-\mu\right)}{1-\Phi\left(3-\mu\right)+\Phi\left(-1-\mu\right)}, & x\in\left(-\infty,-1\right]\cup\left[3,\infty\right),\\ 0, & x\in\left(-1,3\right). \end{cases}](https://s0.wp.com/latex.php?latex=f%5Cleft%28x%3B%5Cmu%5Cright%29%3D%5Cbegin%7Bcases%7D+%5Cfrac%7B%5Cphi%5Cleft%28x-%5Cmu%5Cright%29%7D%7B1-%5CPhi%5Cleft%283-%5Cmu%5Cright%29%2B%5CPhi%5Cleft%28-1-%5Cmu%5Cright%29%7D%2C+%26+x%5Cin%5Cleft%28-%5Cinfty%2C-1%5Cright%5D%5Ccup%5Cleft%5B3%2C%5Cinfty%5Cright%29%2C%5C%5C+0%2C+%26+x%5Cin%5Cleft%28-1%2C3%5Cright%29.+%5Cend%7Bcases%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
As previously mentioned, the formalization of severity involves some kind of notion of accordance between test statistic values and parameter values. For the gapped normal distribution the Karlin-Rubin theorem applies directly: a uniformly most powerful test exists and it’s a threshold test, just as in the ordinary normal model. So it seems reasonable to say that larger values of x accord with larger values of μ even with the gap in the sample space, and the SEV function is constructed for the gapped normal model just as it would be for the ordinary normal model:

It’s interesting to note that frequentist analyses such as a p-value or the SEV function will yield the same result for x = -1 and x = 3. In both these cases, for example,
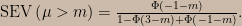
This is because the data enter into the inference through tail areas of the sampling probability density, and those tail areas are the same whether the interval of integration has its edge at x = -1 or x = 3.
The Bayesian posterior distribution, on the other hand, involves integration over the parameter space rather than the sample space. Assuming a uniform prior for μ, the posterior distribution is
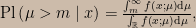
which does not have an analytical solution. We can see right away that the Bayesian posterior will not yield the same result when x = -1 as it does when x = 3 because the data enter into the inference through the likelihood function, and x = -1 induces a different likelihood function than x = 3.
But what about that uniform prior? Does a prior exist that will enable “frequentist pursuit” and bring the Bayesian analysis and the SEV function back into alignment? To answer this question, consider the absolute value of the derivative of the SEV function with respect to m. This is the “SEV density”, the function that one would integrate over the parameter space to recover SEV. I leave it as an exercise for the reader to verify that this function cannot be written as (proportional to) the product of the likelihood function and a data-independent prior density.
So! I have fulfilled the promise I made in my blogging agenda to specify a simple model in which the two approaches, operating on the exact same information, must disagree. It isn’t the model I originally thought I’d have – it’s even simpler and easier to analyze. The last item on the agenda is to subject the model to extreme conditions so as to magnify the differences between the SEV function and the Bayesian approach. This web app can be used to explore the two approaches.
The default setting of the web app shows a comparison I find very striking. In this scenario x = -1 and Pl(μ > 0 | x) = 0.52. (Nothing here turns on the observed value being right on the boundary – we could imagine it to be slightly below the boundary, say x = -1.01, and the change in the scenario would be correspondingly small.) This reflects the fact that x = -1 induces a likelihood function that has a fairly broad peak with a maximum near μ = 0. That is, the probability of landing in a vanishingly small neighbourhood of the value of x we actually observed is high in a relative sense for values of μ in a broad range that extends on both sides of μ = 0; when we normalize and integrate over μ > 0 we find that we’ve captured about half of the posterior plausibility mass. On the other hand, SEV(μ > 0) = 0.99. The SEV function is telling us that if μ > 0 were false then we would very frequently – at least 99 times out of 100 – have observed values of x that accord less well with μ > 0 than the one we have in hand. But wait – severity isn’t just about the subjunctive test result; it also requires that the data “accords with” the claim being made in an absolute sense. If μ = 1 then x = -1 is a median point of the sampling distribution, so I judge that x = -1 does indeed accord with μ > 0.
I personally find my intuition rebels against the idea that “μ > 0″ is a well-warranted claim in light of x = -1; it also rebels at the notion than x = -1 and x = 3 provide equally good warrant for the claim that μ > 0. In the end, I strictly do not care about regions of the sample space far away from the observed data. In fact, this is the reason that I stopped blogging about this – about four years ago I took one look at that plot and felt my interest in (and motivation for writing about) the severity concept drain away. Since then, this whole thing has been weighing down my mind; the only reason I’ve managed to muster the motivation to finally get it out there is because I was playing around with Shiny apps recently – they’ve got a lot better since the last time I did so, which was also about four years ago – and started thinking about the visualizations I could make to illustrate these ideas.
![p_{X,Y}\left(x,y \right )\propto\exp\left[-\frac{1}{2}\left(x^2+y^2\right ) \right ].](https://s0.wp.com/latex.php?latex=p_%7BX%2CY%7D%5Cleft%28x%2Cy+%5Cright+%29%5Cpropto%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x%5E2%2By%5E2%5Cright+%29+%5Cright+%5D.&bg=ccbbaa&fg=000000&s=0&c=20201002)
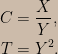
![\begin{aligned}p_{C,T}\left(c,t \right )&\propto\exp\left[-\frac{1}{2}\left(1+c^2\right )t \right ]\\&=\left ( \frac{1}{1+c^2} \right )\left \{ \frac{1}{2}\left(1+c^2\right )\exp\left[-\frac{1}{2}\left(1+c^2\right )t \right ]\right \}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7Dp_%7BC%2CT%7D%5Cleft%28c%2Ct+%5Cright+%29%26%5Cpropto%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29t+%5Cright+%5D%5C%5C%26%3D%5Cleft+%28+%5Cfrac%7B1%7D%7B1%2Bc%5E2%7D+%5Cright+%29%5Cleft+%5C%7B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%281%2Bc%5E2%5Cright+%29t+%5Cright+%5D%5Cright+%5C%7D.%5Cend%7Baligned%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
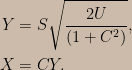
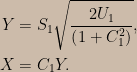
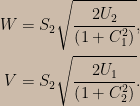

![\begin{aligned}&\Pr\left(\bar{\mathrm{X}}_{4}>165;\mu\right)\Pr\left(\bar{\mathrm{X}}_{4}>q_{4}\left(\alpha,\mu\right)\mid\bar{\mathrm{X}}_{4}>165;\mu\right)\\&+\Pr\left(\bar{\mathrm{X}}_{4}\le165;\mu\right)\Pr\left(\bar{\mathrm{X}}_{100}>q_{100}\left(\alpha,\mu\right)\mid\bar{\mathrm{X}}_{4}\le165;\mu\right)\\=&\left(1-\alpha\right)\left[\Pr\left(\bar{\mathrm{X}}_{4}>165;\mu\right)+\Pr\left(\bar{\mathrm{X}}_{4}\le165;\mu\right)\right]\\=&1-\alpha\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%26%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3Eq_%7B4%7D%5Cleft%28%5Calpha%2C%5Cmu%5Cright%29%5Cmid%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%5C%5C%26%2B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B100%7D%3Eq_%7B100%7D%5Cleft%28%5Calpha%2C%5Cmu%5Cright%29%5Cmid%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5C%5C%3D%26%5Cleft%281-%5Calpha%5Cright%29%5Cleft%5B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%3E165%3B%5Cmu%5Cright%29%2B%5CPr%5Cleft%28%5Cbar%7B%5Cmathrm%7BX%7D%7D_%7B4%7D%5Cle165%3B%5Cmu%5Cright%29%5Cright%5D%5C%5C%3D%261-%5Calpha%5Cend%7Baligned%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
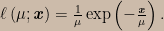
![\ell\left(\mu;\mathbf{\textbf{\textit{x}}}\right)=\frac{1}{\mu}\exp\left(-\frac{\mathbf{\textbf{\textit{x}}}}{\mu}\right)\left[1-\exp\left(-\frac{\mathbf{\textbf{\textit{x}}}}{\mu}\right)\right]^{k-1}.](https://s0.wp.com/latex.php?latex=%5Cell%5Cleft%28%5Cmu%3B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%5Cright%29%3D%5Cfrac%7B1%7D%7B%5Cmu%7D%5Cexp%5Cleft%28-%5Cfrac%7B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%7D%7B%5Cmu%7D%5Cright%29%5Cleft%5B1-%5Cexp%5Cleft%28-%5Cfrac%7B%5Cmathbf%7B%5Ctextbf%7B%5Ctextit%7Bx%7D%7D%7D%7D%7B%5Cmu%7D%5Cright%29%5Cright%5D%5E%7Bk-1%7D.&bg=ccbbaa&fg=000000&s=0&c=20201002)
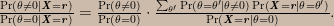
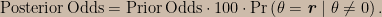
![p\left(x;\mu\right)=\begin{cases} \frac{\phi\left(x-\mu\right)}{1-\Phi\left(3-\mu\right)+\Phi\left(-1-\mu\right)}, & x\in\left(-\infty,-1\right]\cup\left[3,\infty\right),\\ 0, & x\in\left(-1,3\right). \end{cases}](https://s0.wp.com/latex.php?latex=p%5Cleft%28x%3B%5Cmu%5Cright%29%3D%5Cbegin%7Bcases%7D+%5Cfrac%7B%5Cphi%5Cleft%28x-%5Cmu%5Cright%29%7D%7B1-%5CPhi%5Cleft%283-%5Cmu%5Cright%29%2B%5CPhi%5Cleft%28-1-%5Cmu%5Cright%29%7D%2C+%26+x%5Cin%5Cleft%28-%5Cinfty%2C-1%5Cright%5D%5Ccup%5Cleft%5B3%2C%5Cinfty%5Cright%29%2C%5C%5C+0%2C+%26+x%5Cin%5Cleft%28-1%2C3%5Cright%29.+%5Cend%7Bcases%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
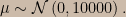
![\pi\left(x;\mu\right)\propto\begin{cases}\exp\left\{ -\frac{1}{2}\left(x-\mu\right)^{2}\right\} \times\chi\left(x\notin\left[x_{0}-\epsilon,x_{0}+\epsilon\right]\right), & \mu\le20,\\\exp\left\{ -\frac{1}{2}\left(x-\mu\right)^{2}\right\} , & \mu>20,\end{cases}](https://s0.wp.com/latex.php?latex=%5Cpi%5Cleft%28x%3B%5Cmu%5Cright%29%5Cpropto%5Cbegin%7Bcases%7D%5Cexp%5Cleft%5C%7B+-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu%5Cright%29%5E%7B2%7D%5Cright%5C%7D+%5Ctimes%5Cchi%5Cleft%28x%5Cnotin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%5Cright%29%2C+%26+%5Cmu%5Cle20%2C%5C%5C%5Cexp%5Cleft%5C%7B+-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu%5Cright%29%5E%7B2%7D%5Cright%5C%7D+%2C+%26+%5Cmu%3E20%2C%5Cend%7Bcases%7D&bg=ccbbaa&fg=000000&s=0&c=20201002)
![\mu\le20\Rightarrow x\notin\left[x_{0}-\epsilon,x_{0}+\epsilon\right];](https://s0.wp.com/latex.php?latex=%5Cmu%5Cle20%5CRightarrow+x%5Cnotin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%3B&bg=ccbbaa&fg=000000&s=0&c=20201002)
![x\in\left[x_{0}-\epsilon,x_{0}+\epsilon\right]\Rightarrow\mu>20.](https://s0.wp.com/latex.php?latex=x%5Cin%5Cleft%5Bx_%7B0%7D-%5Cepsilon%2Cx_%7B0%7D%2B%5Cepsilon%5Cright%5D%5CRightarrow%5Cmu%3E20.&bg=ccbbaa&fg=000000&s=0&c=20201002)