Error Statistics and the Severity Principle, part one: The Way that Denies by Denying
Error Statistics
Error statistics aims to provide a philosophical foundation for the application of frequentist statistics in science. As in any frequency-based approach, error statistics adheres to what I consider to be the fundamental tenet of frequentist learning: any particular data-based inference is deemed well-warranted only to the extent that it is the result of a procedure with good sampling characteristics.
What kind of procedures are we talking about, and what characteristics of those procedures ought we to care about? The error statistical approach distinguishes itself from other frequentist frameworks (e.g., frequentist statistical decision theory) by the answer it gives to that question. Particular attention is paid to tests, by which I mean a procedure that takes some data and a statistical hypothesis as inputs and issues a binary pass/fail result. (As we’ll see, the testing framework easily encompasses estimation by holding the data input fixed and varying the statistical hypothesis input.) The error statistical worth of a test is related, sensibly enough, to the (in)frequency with which the test produces an erroneous conclusion, and, critically, what that error rate indicates about the capacity of the test to detect error in the case at hand. This notion is codified by the Severity Principle.
Modus tollens and maximally severe tests
The most straightforward way to understand the Severity Principle (for me, anyway,) is as an extension of a rule of inference of classical logic that has the delightfully baroque name modus tollendo tollens, or more simply, modus tollens.
To apply modus tollens, one starts with two premises: first, “if P, then Q“; and second, “not-Q“. From these, modus tollens produces the conclusion “not-P“. Modus tollens is also known as the law of contrapositive because contraposition applied to the first premise yields “if not-Q, then not-P“.
For the purpose of exposition, I offer this slight reformulation of modus tollens: the two premises are “if not-H, then not-P” and “P“, and the conclusion is “H“. Here H represents an hypothesis and P represents a passing result from some test of H. The premise “if not-H, then not-P” expresses a property of the test, to wit, that it is incapable of producing an erroneous passing grade. The premise “P” expresses the assertion that for the observed data, the test procedure has produced a passing grade. In the language of error statistics, one says that H has passed a maximally severe test.
“Frequencification” of modus tollens
The above reformulation introduced the notion of a test into the premises, but because the first premise posited a perfect test, the whole idea of a test seemed rather superfluous. But classical logic is silent in the face of imperfect tests; and since learning from imperfect tests is, after all, possible, we seek an extension of modus tollens to imperfect tests.
The first step is to consider the opposite of a maximally severe test. Such a minimally severe test would be one gives a passing grade to H irrespective of the data. We can “frequencify” this notion: for a minimally severe test, we have

or equivalently,
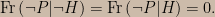
(I use the symbol “Fr” to be clear that I’m writing about relative frequencies.) The analogous frequencification of a maximal severe test is

The equation in the above line captures only the first premise of modus tollens, so it’s a necessary but not sufficient component of the notion of a maximally severe test. To see this, notice that a procedure that always gives a failing grade to H irrespective of the data does satisfy the above equation; however, modus tollens will never apply. The inequality encodes the fact that part of what we mean by the word “test” is that it is at least possible to observe a passing grade, or to put it another way, that there must be some possible data that accords with H.
The key point is that the necessary conditions for a minimally and a maximally severe test are, respectively, Fr(not-P | not-H) = 0 and Fr(not-P | not-H) = 1. This suggests that (provided we’ve checked that Fr(P | H) > 0,) we can measure the severity of a test by the value of Fr(not-P | not-H) .
The Severity Principle
At this point, I’m just going to quote straight from Mayo’s latest exposition of severity:
“Severity Principle []. Data x0 (produced by process G) provides good evidence for hypothesis H (just) to the extent that test T severely passes H with x0.
…
A hypothesis H passes a severe test T with data x0 if,
(S-1) x0 accords with H, (for a suitable notion of accordance) and
(S-2) with very high [frequency], test T would have produced a result
that accords less well with H than x0 does, if H were false or incorrect.”
My previous discussion was based on the idea of pass/fail testing, whereas condition (S-2) is phrased in terms of “accord[ing] less well”, the key word being “less”. Mayo’s definition does not merely introduce the notion of accordance with H — it demands a totally ordered set to express it.
To connect my exposition here with Mayo’s definition, we can now recognize that, just as school exams produce both a numerical grade and a pass/fail categorization, a statistical data-based pass/fail test will (almost always) be a dichotomization of a test statistic that makes finer distinctions, and the choice of dichotomization threshold is essentially arbitrary. Mayo’s definition of a severe test resolves this arbitrariness by placing the threshold for a passing grade right at the observed value of the test statistic. (The threshold is notionally infinitesimally below the observed value of the test statistic, so that H just barely passes. Alas, the reals contain no infinitesimals.)
To make the notion of the severity of a test T of H mathematically precise and operational, we’ll have to get more specific about what is meant by “accords less well”. That will be the topic of part two.

I thought I would add a quick comment to note that I appreciate what you are doing here, even though I haven’t read your posts closely enough to comment very intelligently.
I haven’t got a particularly clear understanding of severity, but it seems to me that Mayo would strongly disagree with this paper:
Hubbard and Bayarri, P Values are not Error Probabilities
Click to access 03-26.pdf
From what I gather severity is an attempt to resolve this issue (I am not sure if it is successful or not)
Can P values be justified on the basis of how they perform in repeated use? We doubt it. For
one thing, how would one measure the performance of P values?” (Berger and Sellke 1987,
p. 136; our emphasis). quote of a quote in the above article…
Thanks for your link and appreciation!
In the debate on the proposition “p-values are error probabilities”, both the pro and con side agree on the mathematical definition of the p-value. Contemplating whether the p-value deserves a certain label is useful when the goal is good communication, but not when the goal is establishing fundamental principles for statistical inference.
I think the state of play can be described thus: the pro side is very clear that the sense in which p-values are error probabilities is relative to hypothetical repetitions of the experiment under a specific, possibly untrue simple statistical hypothesis. They argue that these notional repetitions suffice to make p-values relevant when assessing the warrant given by the data to alternative hypotheses. The con side (usually) agrees that p-values are relevant to statistical inference; they argue that p-values are not error probabilities in experiments that anyone actually carries out, and users of statistical technology often misunderstand this.
The key point is that the teams give the same definition to the p-value but different definitions to “error probability”, and that’s how they end up taking opposite positions on the proposition at issue. Bah.
I guess it is easy here to get caught up in semantics rather than anything more substantial…
I think if a p-value has a repeat sampling interpretation or can be given one is more substantial.
My reading of the debate was that giving a p-value a repeat sampling interpretation requires a clever answer to ‘what exactly it is that repeats’…
… that said, I am skeptical about hypothesis testing (or point estimation) in general so I don’t invest too much time into reading about these issues….
For a p-value to be an error probability does not mean it has what you call a “repeat sampling” interpretation, except perhaps in the sense that one can simulate the relative frequency distribution associated with p-values, under varying hypotheses.
You are skeptical about hypothesis testing? What does that mean? You don’t think conjectures, theories, hypotheses, models can/ought to be tested? Do you accept claims that have not been put to the test?
Mayo: On your first point you seem to be agreeing with Corey, your issue with Berger and Selke (and others) is about what an error probability is (and I was wrong in that apparently nobody asserts that a p-value has a repeat sampling intepretation).
Its difficult to answer your questions in a short space like this. The best I can do is probably to refer you to Frank Lad’s excellent book, Operational Subjective Statistical Methods. I have some sympathy with the criticism you level at some types of Bayesianism (especially the difficulty in interpreting the posterior) but I do consider the type of Bayesianism described in that book to be free from most criticisms of Bayesian philosophy.
The short answer is that I think the more generic principle is to think in terms of what one observation will make you think about likely outcome of other observations you plan to make in the future rather than to think about “conjectures, theories, hypotheses or models”.
While this is the generic principle, much of science applies to modelling exchangeable sequences. If the problem is relatively simple concensus can be arrived at on these types of exchangeable problems, which explains a big portion about how science progresses. While I like the operational subjective approach, I am not necessarily in favour of formal statistical inference, in an exchangeable setting many types of analysis might surfice from exploratory analysis with visualisation to quoting descriptive statistics or a frequentist e.g. hypothesis testing analysis to a formal analysis Bayesian analysis.
I don’t mean to squelch Corey’s paying so much attention to severity, but I feel a bit as if he’s writing an unapproved biography. For example, on this post, logical conditionals are related to probabilistic conditionals, but that won’t work. Next severity is being identified with conditional probabilities, Bayesian style, and this really won’t work.Yet, if I correct one thing, I feel people will assume that I’d have corrected all errors, and yet, I really cannot. I have written long and short items that relate severity to statistical tests and confidence intervals, and I’d like to suggest those items are the only way to avoid inaccuracy, and to get at the idea speedily. Here are 2 discussions:
An informal ~10 page intro from Error and Inference (Mayo and Spanos introduction)
Click to access E&I_The_Error-Statistical_Philosophy.pdf
In the following, since Corey’s readers will have a stat background, skip the first 12 pages and get to severity.
Click to access 2006Mayo_Spanos_severe_testing.pdf
Thanks for your interest.
P.S. And yes, a p-value is an error probability–something we’ve discussed on the blog (also in Senn’s posts), and which neither N-P theorists nor Fisherians deny (never mind J. Berger’s private construal of what Neyman really meant ).
No, it’s just notation: I’m using “Fr( . | H)” instead of, e.g., “Pr( . ; H)”, that’s all. (Even for a Bayesian, H is either true or false and “Fr( H | other stuff )” doesn’t generally make sense, which is why I’ve adopted this notation.)
To put it another way, I’m happy to define “Fr( . | . )” such that the frequencies of events to the left of the vertical bar are to be computed under the assumption that the data arose according to the distribution specified by the hypothesis to the right of the vertical bar. I think this addresses “logical conditionals are related to probabilistic conditionals” too…?
I welcome corrections, however partial; you can always disclaim their comprehensiveness explicitly. I’ll review the links.
Michael Lew’s paper contains references showing that he’s not the only one arguing for the con side of the debate; the paper linked by David Rohde is in there.
Do you disagree with my assessment of the state of play?
I think Corey, SEV is like the Sistine Chapel: mere mortals are supposed to just stand there admiringly and look upon it with rapturous awe.
I think that’s rather unfair — philosophers expect their thoughts to be critiqued.
(Please, Entsophy, substantive comments only in the future — no sniping at Mayo.)
This just follows from “declaring Stat sig (alpha)” (or following a similar “action”) whenever you obtain a result that reaches the alpha level–you will do so with a prob of alpha under Ho. The mathematics doesn’t know if you’ve reported the attained p-vaue or fixed it in advance. It doesn’t change. that’s why N-P, Lehmann, Fisher etc. held that reporting the p-value allows people to apply the level relevant for the inferential context.
J. Berger got it in his head when he reread Neyman one day (I think it’s Neyman 1977, I’m traveling at the moment) that Neyman meant something different from what he meant. Accordingly Berger invented the Frequentist rule or whatever he called it that led dozens of others to repeat the same thing. I remarked on it first in my comment to Berger’s “Could Jeffreys, Neyman, Fisher have agreed on testing…” You can find all these on my “publications” page or search the blog. My limo is pulling up now—gotta run! It’s a stretch!
I don’t disagree with you. It does seem to me that the con side is arguing against the frequentist legitimacy of defining an error rate relative to a post-data quantity. From this point of view, you’re merely restating your definition, so you can’t expect them to treat this counter-argument as dispositive.
The idea that p-values and Type I error rates can’t be identified is not original to Berger — Hubbard and Bayarri cite:
Kalbfleisch, J.G., and Sprott, D.A. (1976), “On Tests of Significance,” in Foundations of Probability Theory, Statistical Inference, and Statistical Theories of Science, eds. W.L. Harper and C.A. Hooker, Dordrecht: Reidel, 259–270.
Corey: conditionals in logic don’t go over into probability conditionals. One example: (A & ~A) -> B is a tautology, whereas P(B|(A & ~A)) is generally undefined, but in any event, not 1.
Aside: If for your Bayesian H is either true or false, then what are the degrees measuring? And does “true” for empirical hypothesis H mean “H adequately captures what is the case (in the real world)” or something like that? I thought Bayesians denied hypotheses were either true or false.
Fr( Event | absurdity ) is undefined, sure. But if you want to break my modus tollens analogy, you’ll have to give me an example that doesn’t condition on absurdity…
Pl( Claim | absurdity ) can be anything in [0, 1] for the same reason that any real value of x solves (0)(x) = 0. We do no damage to Cox-plausibility as an extension of logic by defining Pl( Claim | absurdity ) = 1, if we so choose.
Regarding your aside: the degrees being measured are the degrees of plausibility of H in light of the available information, as formalized by Cox’s postulates. Suppose you asked me what a thermometer was measuring, and I described how the volume occupied by mercury varies with the average kinetic energy of the atoms, and how I could machine a glass tube with a mercury-filled reservoir and narrow cylindrical channel so that the volume variations in some range would result in a perceptible difference in the height of the mercury column in the channel. Would you then reply, “Yes, but what does it measure?”
“True” in Cox-plausibility terms means whatever “A OR not-A” means. By “true” I personally generally mean something like “in accord with reality”. Jaynesians don’t deny that the hypotheses in which we are most interested are the sort which are either true or false.
ETA: I think the kinds of Bayesians who deny hypotheses are either true or false are those who prefer to state probabilities only for observable quantities, in the style of de Finetti and Seymour Geisser. Their frameworks sometimes incorporate parameter-like quantities using exchangeability and the de Finetti representation theorem, but they regard them only as mathematical devices for generating probability distributions for observables.
“Substantive comments only in the future”
Agreed. Terrible habit to get into. I am going to appropriate that “unapproved biography” line though (with attribution of course) since it perfectly captures the thing it was trying to capture.
I liked this post the best so far and thought the “Fr” notation clarifying and unobjectionable. But I guess that’s a matter of taste.
I agree, unapproved biography are les mots justes.
I could pass my posts to Mayo to review before posting, but (i) she’s a busy person, (ii) I want my words to stand or fall on their own, and (iii) I don’t mind public smackdowns (in the sense of Brad DeLong’s “DeLong Smackdown Watch”, the generic title under which he reblogs cogent criticisms of things he’s written).
Reviewing that comment thread at AG’s blog, I see that I picked up the “Fr” notation idea from Wasserman.
Corey:The truth of A or not-A is not-empirical. My puzzle isn’t with the meaning of truth, for non-bayesians. it’s the fact that you’re saying we need only true/false, rather than degrees. That does not seem Bayesian. On the other hand, if you hold that hypotheses and theories are true/false, then I presume you still wish to qualify conjectured hypotheses, claims, theories. The error statistician has a clear way of explicating this on grounds of how well tested they are, the precision and accuracy of estimated quantities within theories, etc. Assessments do not obey the probability calculus. What is plausibility? It is not well-testedness, right?
I definitely did not mean this. Do you consider a moral claim (e.g., “it is wrong to lie”) to be the sort of thing whose truth can be settled empirically? I don’t, and my yakking about truth was just meant to exclude these sorts of propositions from the universe of discourse.
Just as Peano’s axioms serve to give a precise definition of what sort of thing counts as a natural number, Cox’s postulates serve to give a precise definition to (what I mean by) plausibility: it’s a number that is attached to a claim and a state of information; the set of such numbers in a universe of discourse obeys certain manipulation rules that follow from consistency with Boolean algebra.
I’m at a loss to express it more clearly than I already have in my first two posts; if those don’t do it, then read Van Horn, I guess.
But we don’t assign ineffable numbers to claims in finding things out.
Some of us do.
I want to be clear that I would reject the claim that “The error statistical worth of a test is identified, sensibly enough, with the (in)frequency with which the test produces an erroneous conclusion — hence the name “error statistics” (in corey’s post).I have tried to clearly distinguish between this behavioristic construal of error statistics, and the severe testing construal. While control of errors (D.R. Cox’s weak repeated sampling principle) is necessary, it is not sufficient, and fails to capture the goal of the error statistical assessment in the case of scientific inference. Think of my homely weight example….
I have changed the quote in question to a phrase which (I hope) more accurately reflects the severe testing construal. — Corey, Nov 18
I intended no behavioristic construal, which is why I didn’t mention anyone’s behavior, or any commitment to act as if a given hypothesis were true. Upon reviewing Mayo and Spanos 2006 (M&S), I can see how my too-short summation looks a lot like what you have described as the “behavioristic rationale”. Let me state clearly here that severe testing construal is not a behavioristic one.
The “(in)frequency” I was thinking of is the one that appears in (S-2). I meant “identified” in a much more limited, mathematical sense, as in the equality tagged with footnote 15 on page 337 of M&S.
Corey,you’re missing my point. What I’m denying is that a method’s good performance or low error rates or the like are sufficient for severity. (I wasn’t claiming you identified test results with an adjustment of behavior or “acting” in a certain way. Actually, that notion of Neyman’s is sufficiently flexible to fit any epistemic standpoint one would want.)
I distinguish the 3 P’s: probabilism, performance, and probativeness.
And there I was, thinking I was admitting it…
Corey had said, “Mayo’s definition of a severe test resolves this arbitrariness by placing the threshold for a passing grade right at the observed value of the test statistic”. As a rudimentary introduction to severity computations in EGEK I suggested considering this dichotomy (the book is written for philosophers with no stat background). That’s not SEV in general. To evaluate SEV (for a test, a question, data, model) requires considering many difference inferences: those that have passed well, decently,and those for which the test provides bad evidence no test (BENT).
Actual severity values rarely matter: the idea of good/bad evidence is a threshold concept, where at minimum we discount terribly insevere results. Incidentally, Corey and I once had this discussion about whether and how a Bayesian can capture the notion of a terrible test–the kind of pseudoscience some people have lately been discussing on my blog. i don’t see that it can capture the notion, whereas it is exactly captured by error statistical requirements and severity.
Severity Requirement (weak): If data x agree with a hypothesis H, but the method would have (almost surely) issued so good a fit even if H is false, then the data x provide poor evidence for H. It is a case of bad evidence/no test (BENT).
The “almost surely” acknowledges that even if the method had some slim chance of producing a disagreement (or a worse fit) when H is false, we still regard the evidence as quite lousy. Little if anything has been done to rule out erroneous construals of data. As weak as the severity requirement is, it is stronger than requiring merely that a hypothesis be logically falsifiable, the familiar Popperian position. We would condemn a test that had low capability of obtaining or recognizing or admitting anything but evidence in favor of a hypothesis.
“Mayo’s definition of a severe test resolves this arbitrariness by placing the threshold for a passing grade right at the observed value of the test statistic”
Here I’m really just thinking of that ol’ equation footnoted 15 on page 337 of M&S.
OK, here’s the weight example, and then i should disappear….
Above I mentioned the weakest version of the severity principle. It is negative, warning us when BENT data are at hand, and a surprising amount of mileage may be had from that negative principle alone. In fact, I think you can live with just the negative part, if you were so inclined. The positive counterpart takes x as an indication of, or evidence for, a claim H to the extent that H has passed a severe test with x. This can be achieved by what may be called an argument from coincidence. The most vivid cases occur outside formal statistics—the entire philosophy of inductive inference is continuous between formal statistical and non-statistical cases. Nearly all (good) science, so far as i can see–if it uses formal statistics at all–weaves in and out between formal and informal and qualitative inquiry, and one’s account of statistical inference should seamlessly accommodate the interconnected flow of the different levels.
A variant on my weight examples, discussed in many places, is described by David Cox and I:
“Suppose that weight gain is measured by well-calibrated and stable methods, possibly using several measuring instruments and observers and the results show negligible change over a test period of interest. This may be regarded as grounds for inferring that the individual’s weight gain is negligible within limits set by the sensitivity of the scales. Why? While it is true that by following such a procedure in the long run one would rarely report weight gains erroneously, that is not the rationale for the particular inference.” (Mayo and Cox 2010, 256)
Rather, the error capacities of the weighing procedure inform us about what could and could not have brought about these results right now. It would be a preposterous coincidence if all the scales registered even slight weight shifts when weighing objects of known weight—a 4 ounce bottle of perfume—and yet were systematically misleading when applied to an object of unknown weight.
Nor is it merely the improbability of all the results; it is rather like denying an evil demon has read my mind just in the cases where I do not know the weight of an object, and deliberately deceived me.
The argument indicating no weight gain is an example of an argument from coincidence to the absence of an error, what I call:
Arguing from error: There is evidence an error is absent to the extent that a procedure with a very high capability of signaling the error, if and only if it is present, nevertheless detects no error.
Methods that enable strong arguments to the absence (or presence) of an error I call strong error probes.
For any inquiry we split off (i) a primary question (ii) problems of statistical inference, and (iii) problems of data. Whether considered stages of inquiry, levels, or clusters of problems, an adequate philosophy of statistical inference should be prepared to distinguish severity issues at all three.
The severity scrutiny is based on myriad well corroborated claims and methods that reside in a background tool-kit that I call a repertoire of theories, techniques, and information about the phenomenon. It doesn’t to include everything in the kitchen sink, but a handful of canonical problems, flaws, and foibles relevant to the type of primary question at hand.
In addition to our severity principle, there’s one more thing I appeal to: the goal of finding things out. To be blocked by cartesian demon explanations in the face of strong arguments from coincidence, we can show, would prevent finding things out.
It seems to me that the thermometer analogy used above for what the Bayesian models measure is not quite right– The thermometer measures temperature, a quantity that varies quite a bit, by responding in a predictable way to the amount of heat present (which determines the temperature value). But, you say that Bayesians see a claim (hypothesis) as either true or false, but are using a measure (from the model) that responds somehow to the degree of support from the data. Thus, the Bayesian computation is not measuring in response to how true the hypothesis is, tracking reliably the truth level as a thermometer tracks the temperature value. (Temperature varies, truth does not.) The hypothesis can be true and the evidence weak or vice versa. I think it is this sort of distinction that confuses a lot of us.
The point of the analogy is that I’ve described all the moving parts of the device. There’s nothing left to explain.
“But, you say that Bayesians see a claim (hypothesis) as either true or false, but are using a measure (from the model) that responds somehow to the degree of support from the data. Thus, the Bayesian computation is not measuring in response to how true the hypothesis is, tracking reliably the truth level as a thermometer tracks the temperature value. (Temperature varies, truth does not.)”
All correct. The Bayesian computation is measuring in response to how plausible the data are under various hypotheses, tracking reliably the plausibility level of those hypotheses. (And the plausibility of an hypothesis does vary.)
I took the point of the analogy to be that Bayesian models measure the truth like a thermometer measures temperature. But Bayesian models are not at all like a thermometer in a fundamental respect, as explained (and I acknowledge your agreement with the latter portion above). My point is that these kinds of analogies mislead many of us, or at least give us a bit of confusion for awhile. Bayesian models are really not like a thermometer, as they do not measure the truth as though it is temperature. This analogy suggest I read a posterior probability as a reliable measurement of the truth, when I should do nothing of the kind (because I must evaluate a posterior according to whether it has any meaningful value whatsoever given how it was derived…). I suspect you would agree in principle, as you have a healthy regard for establishing the accuracy/reliability of your models before drawing conclusions.
I guess all I can say is that I do my best to get my ideas across, but communication across a conceptual divide is always a risky business…
Anyway, thanks for taking the time to read this stuff. Would you say that it answers your question about why I persist in calling my analysis “Bayesian” even though I am willing to do error-checking inconsistent with so-called “subjective Bayesian” philosophy?
Yes, I think I understand it better. But, it seems to me that you have more in common with likelihoodist and error statisticians than what has been called Bayesian for the past century, your use of conditional probability notwithstanding. I guess it depends on what you prioritize in the “taxonomy” of statistical approaches. I tend to see the underlying philosophy as the primary basis.
Pingback: How “Severity, part one” got Mayo wrong (and a preview of “Two Severities”) | It's chancy.
Pingback: Two Severities? (PhilSci and PhilStat) | Error Statistics Philosophy