A foundation for Bayesian statistics, part one: Cox’s theorem
(I’m frustrated with the length this post and how much time it’s taking me to finish, so I’m splitting it into two parts.)
I subscribe to a school of thought some call “Jaynesian” after Edwin T. Jaynes. Its foundation is a theorem of Richard T. Cox, a physicist who studied electric eels, not to be confused with the eminent statistician Sir David R. Cox. Since my first project will be to engage with Professor Mayo’s diametrically opposed views on the proper way to use (and think about the use of) statistics in science, it seems worthwhile to describe the theorem and the reasons I take it to be foundational to statistics — of the Bayesian variety, at least.
Background
This section is somewhat disjointed; I chose conciseness and links over a well-written and complete introduction.
Cox sought to formalize the notion of the plausibility of a claim. (Following Professor Mayo, I use “claim” in preference to “assertion” or “proposition”.) The kinds of claims I’m talking about are those that admit two extremes of plausibility: these kinds of claims could either be known to be true, and thus be as plausible as it is possible to be; or they could be known to be false, and thus be as implausible as it is possible to be. In particular, I’m not talking about the kinds of claims that can still be under dispute once all the relevant facts are known, e.g., aesthetic or moral judgments.
Even in the times of antiquity, we knew how to guarantee that only true conclusions would be inferred from true premises. But absent any premises, the rules of that method — the syllogisms of Aristotelian logic — cannot operate; to get out something worthwhile, we have to provide worthwhile input. In likewise fashion, we need some background knowledge — oh heck, let’s just call it prior information — on which to base the assessment of the plausibility of a claim.
Boolean algebra provides rules for manipulating arbitrary combinations of conjunctions (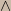

So that’s the background. Next, I’ll give Cox’s postulates, a statement of the theorem, and a high-level overview of the proof. In the post following this one, I’ll discuss why I think the postulates are reasonable and how the resulting perspective guides my approach to statistics.
Cox’s Theorem
I’ll refer to quantities of the type considered by Cox as Cox-plausibilities to distinguish them the informal notion of plausibility. (Cox, writing in 1946, used the term “likelihood” which I will avoid for obvious reasons.) But first, I need some notation: upper-case letters will refer to claims; I’ll use X as the symbol for some generic prior information. For Cox-plausibilities I’ll use, e.g., the symbol A|X to represent the the (real-valued) Cox-plausibility of claim A evaluated on prior information X.
The following five postulates set out the properties that a system of Cox-plausibilities must have. They are:
- Cox-plausibilities are real numbers.
- Consistency with Boolean algebra: if two claims are equal in Boolean algebra, then they have equal Cox-plausibility.
- There exists a conjunction function f such that for any two claims A, B, and any prior information X,
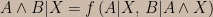 .
.- There exists a negation relation. (Okay, it’s actually a function too.) For now I defer giving it a symbol; in words, it says that the Cox-plausibility of the negation of a claim is a function of the Cox-plausibility of the claim (all relative to the same prior information).
- The negation relation and conjunction function (and their domains) satisfy technical regularity conditions.
Succinctly stated, Cox’s theorem is: any system of Cox-plausibilities is isomorphic to probability.
The proof as seen from 30,000 ft
Conjunction is associative in Boolean algebra:
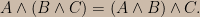
The consistency postulate (and the regularity conditions on the domain of the conjunction function) then require that the conjunction function obeys a functional equation sometimes called the Associativity Equation:
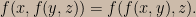
The Associativity Equation plus the regularity conditions imply that there must exist a strictly increasing invertible function g such that

This equation is significant enough to deserve its own name: it’s the product rule. Note that for the function p, defined as
![p(x)\equiv \left[ g(x)\right] ^k,\, k>0,](https://s0.wp.com/latex.php?latex=p%28x%29%5Cequiv+%5Cleft%5B+g%28x%29%5Cright%5D+%5Ek%2C%5C%2C+k%3E0%2C&bg=ccbbaa&fg=000000&s=0&c=20201002)
the product rule still holds.
The negation relation can now be stated as: there exists a function h such that
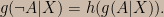
Together, the consistency requirement, the product rule, and the negation relation yield another functional equation:
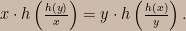
Invoking those regularity conditions again, the general solution of the above equation is
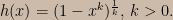
Stated in terms of p, the above equation is:

which can be rearranged to give the sum rule:

Taken together, the sum rule and product rule are the usual starting point for expositions of probability theory, so that’s the whole thing.

It’s number (3) that probably (Cox-plausibility?) leaves people cold. Although from looking at real examples of alternatives to probabilities and seeing how they fail, (3) gets foisted on us ultimately by a consistency requirement. We want, and practioners will demand, that answers be the same if they’re conditional on equivalent information. Maybe replacing (3) with such a requirement would get more traction?
I’ll go over a bit of the reasoning that leads to (3) in my second post, and I’ll give links to further reading.
I’ve seen people balk at (1)…
Hi Corey, thanks for this; a good start in my opinion.
I can see how people balk at (1). How acceptable this is depends on how universal statements are made from interpreting the theorem. I’m all happy to have a theorem that shows what follows from (1) and some other assumptions like these and to reflect on under what circumstances and for what reasons I’d accept the assumptions, but if somebody asks me to *universally accept* them (which some people tend to do implicitly when interpreting such theorems, making statements like “from Cox’as theorem we know that plausibility formalisations have to be probabilities”), that’d be a different story.
Apart from that, I’d be particularly curious if something not so harmless is hidden in (5). The word “technical regularity condition” in my opinion doesn’t imply automatically that they don’t have relevant implications.
Jaynes has a good discussion of reasons for adopting (1) in the appendices of PTLOS. Those reasons are basically analogous to the reasons for adopting axioms 1 and 2 of the VMN utility theorem. Completeness and transitivity of plausibility assessments (rather than preferences on lotteries) get you to a total order, and hence to the reals.
I impugn the sanity of anyone who wants to model their own reasoning using intransitive plausibility assessments. Completeness is more debatable.
Much of the recent work on “theorems in the style of Cox” focuses on weakening or making more natural those regularity conditions; links will be forthcoming.
“I impugn the sanity of anyone who wants to model their own reasoning using intransitive plausibility assessments.”
I actually wonder whether transitivity looks so “natural” not because of anything in the nature of “plausibility”, but rather because we’re so used to using it in a transitive manner (and implicitly tend to think of it as a quantity, which would make the reasoning circular).
What do you think about the sanity of those who came up with imprecise/interval probabilities?
OK, I see that the problem with interval probabilities is not transitivity, but universal comparability.
Just so.
(If we didn’t assume transitivity, consistency with Boolean logic would force it on us anyway.)
I’m really surprised to hear you are interested in claims that are known to be true or known to be false—is that once and for all?
Fortunately, the supposition that we must build on assumptions, that we must have firm foundations (getting firmer all the time!) may be rejected. We can conjecture and learn by trial and error, thereby gaining highly reliable results from highly unreliable conjectures.
I didn’t write “are known” — I wrote “could be known.” I’m trying to narrow the universe of discourse to which the postulates apply to claims like “the information that determines ribonuclease A’s tertiary structure is found in ribonuclease A’s amino acid residue sequence” or “abiogenesis has occurred somewhere other than Earth” or “on November 10 at 11:00am, rain will be falling on the roof of my house”.
The postulates don’t serve as assumptions that we build on as we accumulate knowledge. They serve to define what it is I’m talking about when I state that some claim has a high probability (given some prior information at my disposal).
I think it’s absurd to have to start an account of learning about the world by stipulating what we can learn about the world. It sounds akin to logics of induction that tried to map out all observable predicates, function , relations ahead of time to assign probabilities to states.
And what DO you mean when you claim a high prob given some prior info? Is the prior info known?
I agree, it would be absurd to start an account of learning about the world by stipulating what we can learn about the world. Good thing I’m not doing that, eh?
(Hint: Laying out the syllogisms of classical logic does not stipulate anything about what we can learn about the world.)
When I state that a claim has a high prob given some prior info, I mean that it is highly plausible in light of that information. The prior info may be known to me, or conjectural, or not known at all, just as in an application of logic, the truth of a premise can be known to me, or conjectural, or not known.
Now all you have to do is define plausible.
Indeed — hence this post and its sequel; the former formalizes what I mean by the colloquial term “plausibility”, and the latter (on which you have offered no comment…?) explains the reasons I find this formalization intuitively compelling, much as your explanations of error statistics start with an examination of various severe but not perfect tests and then abstract out the Severity Principle.
Am I right in thinking that your account does not consider aleatory claims such as ‘the next toss of this coin will be heads’?
No, you are not correct. Those are precisely the sorts of claims that are considered.
You might want to clarify your “I’m not talking about the kinds of claims that can still be under dispute once all the relevant facts are known … .” I am thinking of global warming, stimulus versus austerity, etc.. Are these within your scope?
But then, what do you make of Ellsberg or Allais?
Yes, those are within the scope. I consider outcomes under counterfactual setups to belong to the set of “relevant facts” — if these could be known precisely, we could settle causal claims.
Aesthetic claims (e.g., Black Sabbath is a better band than Cake) and moral claims (e.g., lying is always a moral transgression) are two examples of kinds of claims that are out of scope.
Ellsberg and Allais demonstrate that human beings don’t operate as Bayesian agents (unless they explicitly work through the calculations using what Kahneman calls “System 2”). This isn’t a problem for my espousal of Bayes any more than the fact that people commit logical fallacies is a problem for my espousal of logic.
I take it, then, that your approach is normative rather than objective or subjective. But the Ellsberg examples seem to call your norm into question. It is true that Kahneman takes your view, but this seems to beg some important questions. On my blog (djmarsay.wordpress.com) I am collecting claimed justifications of your norm together with refutations. I would be happy to consider more.
Regarding (4), the existence of the negation function.
Consider Bel(A) for a proposition A, where Bel is the Dempster-Shafer belief function. (Dempster-Shafer theory is often described as giving two values to each proposition, the “belief” and the “plausibility”, but we’re going to look at just the belief function).
(4) is where Bel fails, and thus is not isomorphic to probability theory.
I’d like to know your thoughts on, does this really mean that Bel is an inconsistent or irrational belief function?
For example, let’s say my degrees of belief are given by Bel. I say, “Bel(Next coin flip is heads) = 0.5, and Bel(Next coin flip is tails) = 0.5. Furthermore, Bel(Trump wins the next election) =0.5, and Bel(Trump loses the next election)=0.3”. Cox happens to be present, and exclaims, “let S be the function mapping your belief in a proposition to your belief in its negation. First you say S(0.5)=0.5, and then you say S(0.5)=0.3. Inconsistent!” To which I reply, “there does not exist such a function. Why should there?”
So, would you back up Cox in this argument, and say I have made some mistake? If so, how would you explain it to me?
People actually seem to use Dempster-Shafer theory. It’s not OBVIOUSLY bad to fail (4).
The version of (4) stated above goes hand in hand with (1). A version of (4) that stands independent of (1) would be “Let X be the set of things used to encode/represent uncertainties; there exists a function h:X->X that relates Uncertainty(A) to Uncertainty(not-A)”. And indeed, Dempster-Shafer theory does satisfy that desideratum.
In my second post on the topic I describe why I prefer to use real numbers to represent uncertainty rather than, say, pairs of real numbers or lattices or what have you. In that post I recommend reading Kevin Van Horn’s guide to Cox’s theorem (which you can find at http://ksvanhorn.com/bayes/papers.html along with comments by Shafer and a rejoinder) for a more in-depth discussion of these issues. IIRC I got the observation that Dempster-Shafer theory does in effect satisfy (4) from Van Horn, but I don’t remember exactly where.
“Dempster-Shafer theory does satisfy that desideratum”
The Dempster-Shafer belief function does not satisfy that desideratum. The pair (Bel(A), Plaus(A)) where Plaus(A)=1-Bel(~A) does, trivially; is this what you have in mind?
I agree that it’s good to use real numbers, rather than pairs etc. I’m asking what’s so bad about your real number being the Dempster-Shafer belief function, which doesn’t satisfy (4).